Building a Second Brain with LLMs
I didn’t plan to build a second brain tonight. I stumbled on Andrej Karpathy’s LLM Wiki gist — published 6 days ago, already 5000+ stars. Two hours later I had a working knowledge graph of my own work running in Obsidian.
Here’s exactly what I built and how.
The problem with RAG
Most LLM + personal knowledge setups work like this:
source → chunks → vectors → retrieve at query time → LLM reasons from scratchEvery query starts cold. The LLM re-derives answers from raw chunks every single time. Nothing accumulates. Ask the same question 100 times; it does 100x the work.
Karpathy’s insight is a single distinction:
RAG retrieves. LLM Wiki compiles.
Instead of storing chunks, the LLM reads your source once, understands it, and writes structured markdown pages — summaries, entity pages, cross-references, contradictions flagged. The wiki becomes a persistent, compounding artifact. Every new source makes it richer. Every good answer gets filed back in.
The human curates sources and asks questions. The LLM does all the bookkeeping.
Architecture
Three layers:
| Layer | What it is | Who writes it |
|---|---|---|
raw/ | Immutable source documents | You |
wiki/ | Structured markdown pages | LLM |
CLAUDE.md | Schema + conventions + workflows | You + LLM co-evolve |
The wiki is just a git repo of markdown files. Obsidian is the renderer. Claude Code is the architect — it decides what pages exist, what they contain, and how they connect.
Directory structure
second-brain/
├── CLAUDE.md
├── raw/
│ └── assets/
└── wiki/
├── index.md # master catalog — LLM reads this first on every query
├── log.md # append-only ingest history
├── projects/ # one page per active repo
├── data-engineering/ # Spark, Iceberg, Delta, DuckDB
├── infra/ # Databricks, Terraform, AWS
├── ai/ # LLMs, RAG, agents, MCP
└── synthesis/ # cross-domain analysisCLAUDE.md — the schema file
This is the key piece. It tells Claude Code how to structure pages, what frontmatter to use, and how to maintain the wiki. Without it the LLM is a generic chatbot. With it, it becomes a disciplined wiki maintainer.
# Wiki Instructions
You are the maintainer of this wiki. When given a source to ingest,
follow the schema below. Always update index.md and append to log.md.
## Frontmatter
### projects/<slug>.md
---
title: ""
status: active | paused | archived
repo: ""
stack: []
domain: data-engineering | infra | ai
summary: ""
---
### domain pages
---
title: ""
tags: []
related_projects: []
last_updated: YYYY-MM-DD
---
## Log Format
## [YYYY-MM-DD] ingest | <title>
### What
### Why / decision
### Links
## Conflict Resolution
If a new source contradicts an existing wiki page:
1. Do not overwrite the old information immediately.
2. Create a `## Contradictions / Evolution` section at the bottom of the page.
3. Note the discrepancy: "Source [A] claims X, but Source [B] claims Y."
4. If one is clearly an update (e.g. a version change), move old info to an
`## Archive` foldout and update the main summary.
## File Verification
Always use `find wiki/ -name "*.md"` to verify file existence rather than
relying solely on index.md — the index may lag on large ingest sessions.The conflict resolution rule matters more than it looks. Without it the LLM silently overwrites your past thinking. With it, your wiki tracks how your understanding evolved over time:
2024: "Use Spark for everything."
2026: "Spark is overkill; use DuckDB for local analytics."Instead of losing the Spark context, the wiki writes: “Evolved from Spark-heavy infra to local-first DuckDB for cost-efficiency.” That’s the synthesis layer.
Setup
mkdir -p ~/second-brain/{raw/assets,wiki/{projects,data-engineering,infra,ai,synthesis}}
touch ~/second-brain/wiki/index.md
touch ~/second-brain/wiki/log.md
touch ~/second-brain/CLAUDE.md
# paste schema into CLAUDE.mdOpen ~/second-brain as a vault in Obsidian (File → Open Vault → Open folder as vault). Then:
cd ~/second-brain
claudeFirst ingest
Once Claude Code is running, give it a natural language instruction — ingest is not a CLI subcommand, it’s a prompt you type to the agent:
ingest this source: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94fClaude Code fetches the gist, extracts the architecture, use cases, and key distinctions, and writes wiki/ai/llm-wiki-pattern.md. It updates index.md and appends to log.md. One source; multiple pages touched.
The log entry looks like:
## [2026-04-10] ingest | LLM Wiki Pattern (Karpathy)
### What
Created wiki/ai/llm-wiki-pattern.md. Initialized directory structure.
### Why / decision
First source. Placed in ai/ — primarily about LLM-driven knowledge management.
### Links
- Source: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
- Wiki page: ai/llm-wiki-pattern.mdIngesting your own work
The real value comes when you ingest your own projects and history.
ingest this source: https://github.com/chanukyapekala/clipai
ingest this source: https://github.com/delta-skillsNote on large repos: A large repository will exceed Claude’s context window in a single pass. For big sources, guide the agent explicitly: “process this repo directory by directory, starting with the README and core source folders.” This prevents truncated synthesis.
Ingesting your Claude Code conversation history is a killer move — but comes with a caveat:
ingest my claude history from ~/.claudePrivacy warning: Your Claude history likely contains API keys, temporary tokens, or internal details. Before the LLM commits anything to a git-versioned wiki, scan the output:
grep -r "sk-\|Bearer\|password" wiki/and remove sensitive lines. Keep your wiki repo private if in doubt.
That said — once sanitized, this single ingest compiles everything you’ve built, every decision you’ve made, every technology you’ve explored into structured wiki pages automatically.
The graph
After ingesting my Claude history and a few repos, Obsidian’s graph view showed:
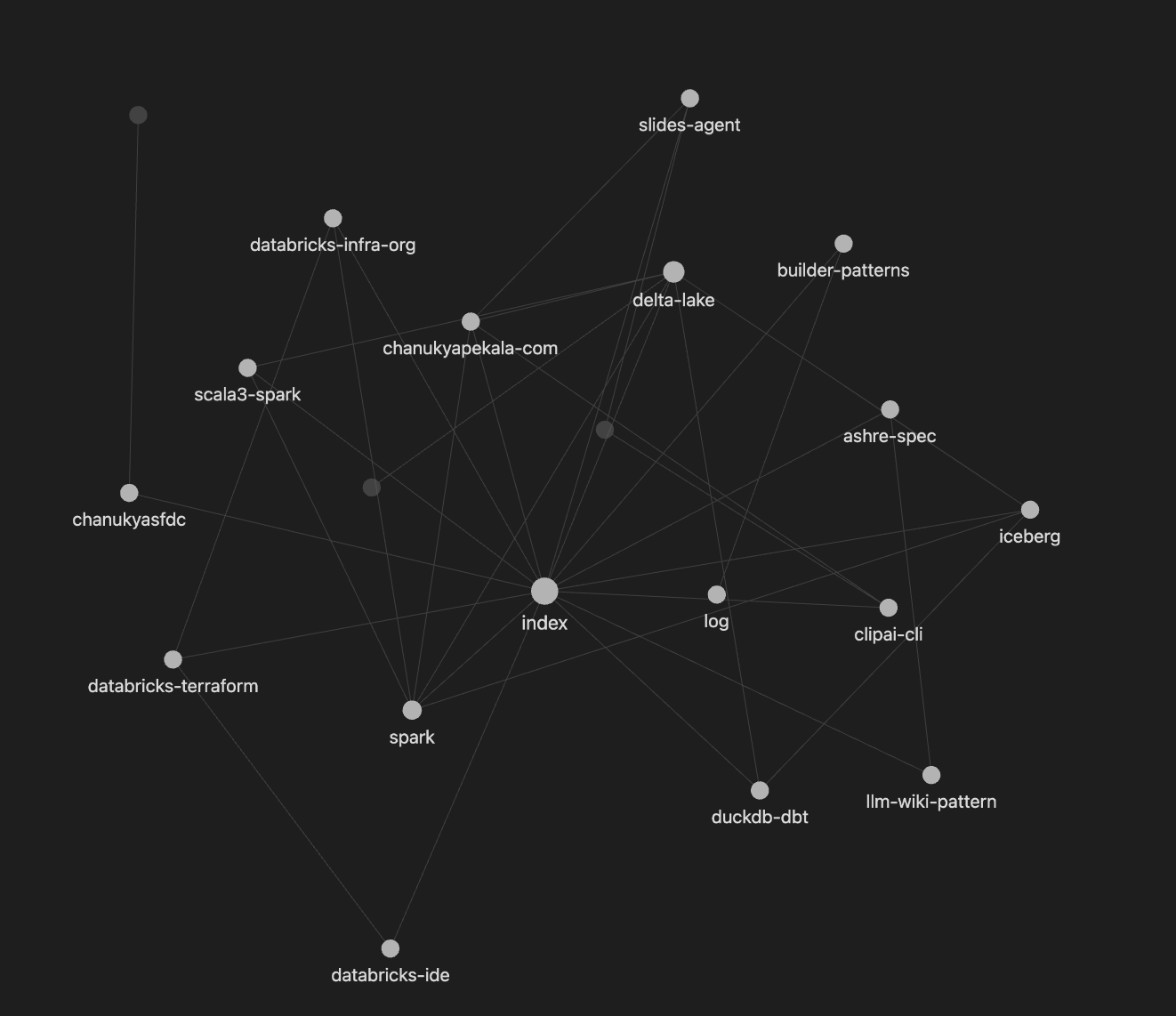
delta-lake → databricks-terraform → iceberg → duckdb-dbt → ashre-spec → clipai-cli → slides-agent
All connected. Obsidian renders the graph from [[wikilinks]] — but Claude Code is the architect that decided those connections exist. The LLM wrote the topology; Obsidian draws it.
The moment it clicked
I asked Claude Code to synthesize patterns across my projects. It surfaced 8 things without any prompting:
- Poetry as my default Python stack
- Local-first, offline-capable tooling preference (Ollama over API keys)
- Learning-through-building as a consistent method
- Personal itch → publishable tool as a recurring arc
- Deliberate adoption of emerging tools before mainstream (Scala 3, DuckDB, Iceberg, Astro)
Things I knew implicitly but had never articulated.
A RAG system would have returned chunks about Poetry and DuckDB. The wiki returned insight about how I build.
Operations
Ingest — give Claude Code a source URL or file path. It reads, extracts, writes pages, updates index and log. One source can touch 10–15 pages.
Query — ask against the wiki:
what do I know about MCP patterns from my own work?
what are the tradeoffs between Genie Code and CLI for my pipelines?Claude Code reads index.md, finds relevant pages, synthesizes with citations. File good answers back:
save this analysis as wiki/synthesis/genie-vs-cli.mdLint — periodic health check:
audit my wiki for orphan pages, broken links, and contradictionsWhat about search at scale?
Right now index.md is enough — Claude Code reads the full catalog on every query. Works reliably up to ~100 pages.
Before you even hit 100 pages, instruct Claude Code to verify file existence with find rather than trusting the index alone — the index can lag during large ingest sessions. This is already in the CLAUDE.md above.
When the wiki grows beyond ~100 pages, qmd adds a local search layer — BM25 + vector hybrid with an MCP server. Claude Code calls it as a native tool instead of scanning index.md. Add it when the wiki earns it.
Version it
cd ~/second-brain
echo "raw/\n.manifest.json\n.env" > .gitignore
git init
git add wiki/ CLAUDE.md .gitignore
git commit -m "initial wiki"
git remote add origin https://github.com/<you>/second-brain.git
git push -u origin mainKeep it private if you’ve ingested Claude history. Every ingest is a commit. You can watch your knowledge base grow over time.
Why this works
The tedious part of maintaining a knowledge base is not the reading or the thinking — it’s the bookkeeping. Updating cross-references, keeping summaries current, flagging contradictions. Humans abandon wikis because the maintenance burden grows faster than the value.
LLMs don’t get bored. They don’t forget to update a cross-reference. They can touch 15 files in one pass.
The wiki stays maintained because the cost of maintenance is near zero.
Karpathy traces the idea back to Vannevar Bush’s 1945 Memex — a personal knowledge store with associative trails between documents. Bush’s unsolved problem was who does the maintenance. Turns out: the LLM.
Original gist by Andrej Karpathy → gist.github.com/karpathy/442a6bf555914893e9891c11519de94f